Infográfico de e-commerce dos earbuds Apple Pods Pro 3

Mais Infográficos
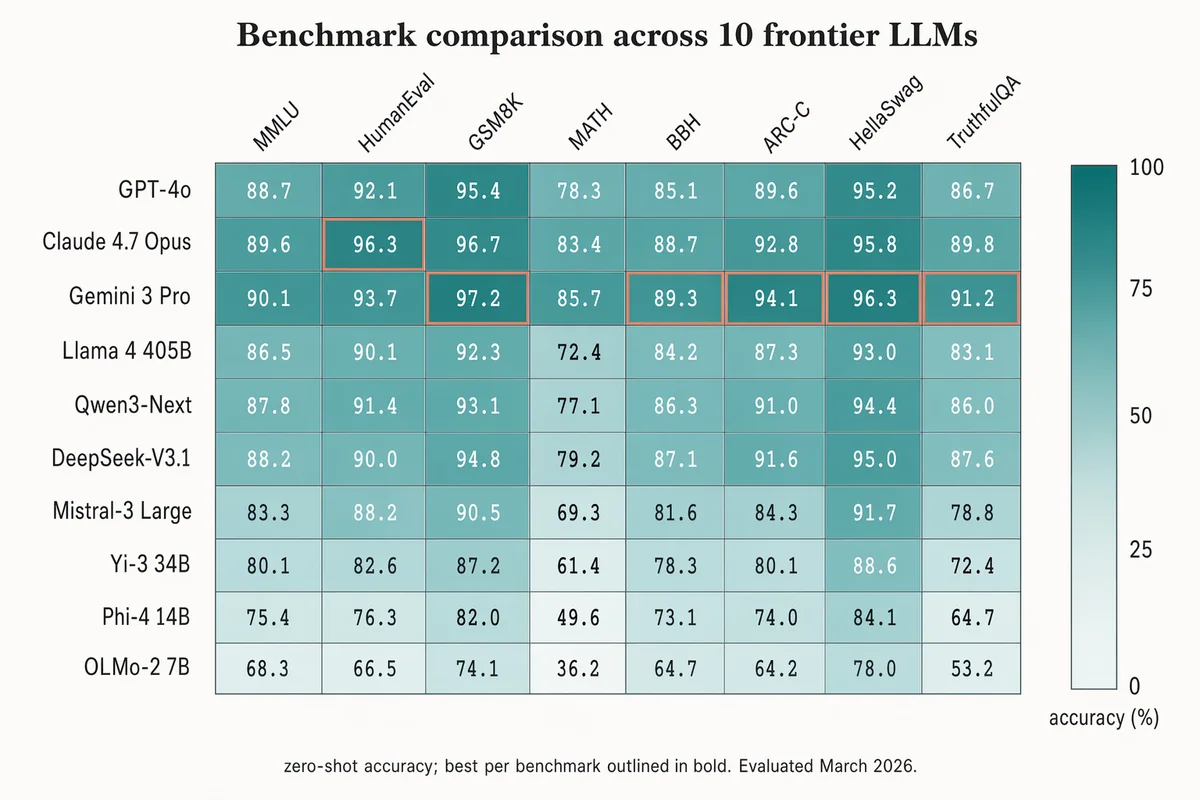
Mapa de calor de comparação de benchmarks
Landscape 16:9 heatmap matrix of models × benchmarks. Columns (rotated 45°): "MMLU", "HumanEval", "GSM8K", "MATH", "BBH", "ARC-C", "HellaSwag", "TruthfulQA". Rows (right-aligned sans-serif): "GPT-4o", "Claude 4.7 Opus", "Gemini 3 Pro", "Llama 4 405B", "Qwen3-Next", "DeepSeek-V3.1", "Mistral-3 Large", "Yi-3 34B", "Phi-4 14B", "OLMo-2 7B". Each cell filled with dusty-teal gradient proportional to score; numeric value in each cell (e.g. "72.3", "88.1"). Best score per column outlined in 1.5px soft-terracotta. Vertical color bar on the right with ticks "0", "25", "50", "75", "100" and label "accuracy (%)". Title: "Benchmark comparison across 10 frontier LLMs". Subtitle: "zero-shot accuracy; best per benchmark outlined in bold. Evaluated March 2026."
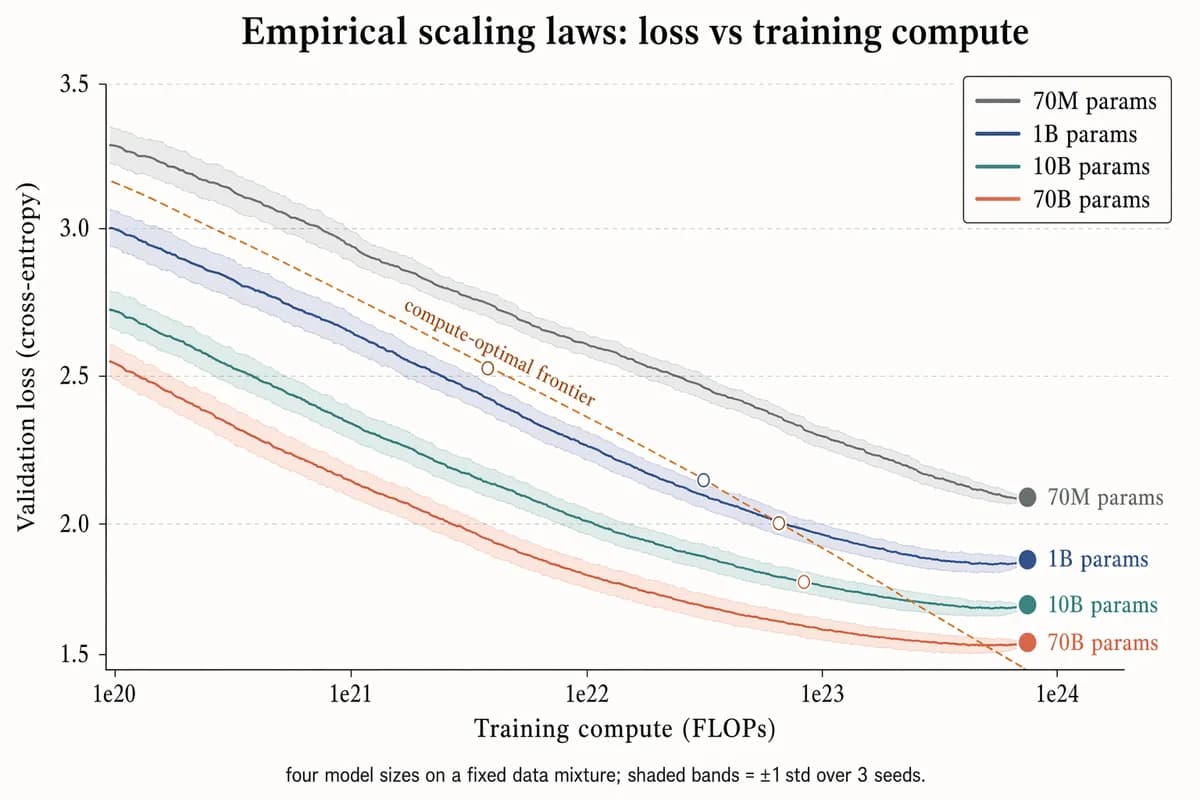
Gráfico empírico de leis de escala
Landscape 16:9 log-scaled plot of training loss vs compute, four curves for different model sizes. X-axis "Training compute (FLOPs)" with log ticks "1e20", "1e21", "1e22", "1e23", "1e24". Y-axis "Validation loss (cross-entropy)" with linear decreasing ticks "3.5", "3.0", "2.5", "2.0", "1.5". Four descending curves with ±1σ shaded bands, labels near tails: "70M params" (slate gray), "1B params" (muted navy), "10B params" (dusty teal), "70B params" (soft terracotta). Warm-copper dashed diagonal line labeled "compute-optimal frontier"; open circles at isoflop crossover points. Legend box top-right. Title: "Empirical scaling laws: loss vs training compute". Subtitle: "four model sizes on a fixed data mixture; shaded bands = ±1 std over 3 seeds."
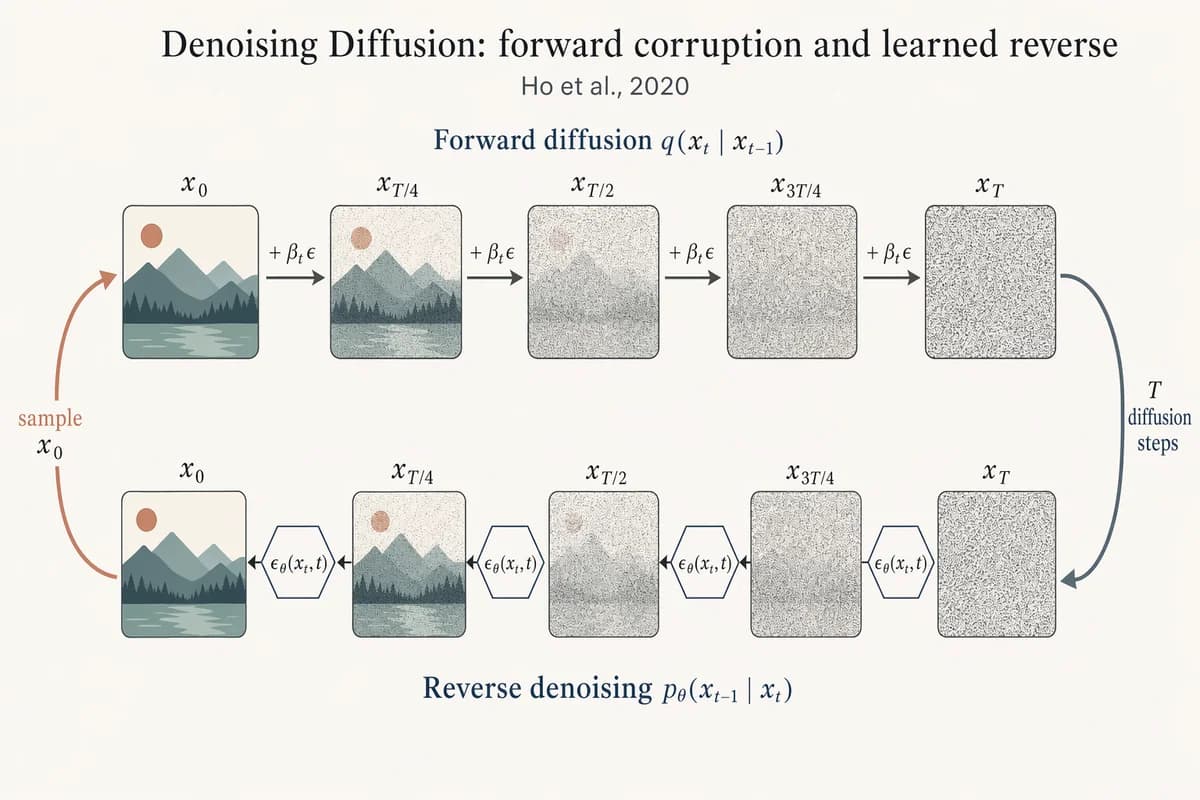
Cadeia direta/reversa de difusão com remoção de ruído
Landscape 16:9 academic figure of diffusion forward + reverse chains, two horizontal chains stacked vertically. TOP chain (left→right) labeled "Forward diffusion q(x_t | x_{t-1})": five frames "x_0", "x_{T/4}", "x_{T/2}", "x_{3T/4}", "x_T" progressing from a crisp small mountain-sun landscape to pure Gaussian noise. Arrows between frames labeled "+ β_t ε". BOTTOM chain (right→left) labeled "Reverse denoising p_θ(x_{t-1} | x_t)": same five frames in reverse, with a small hexagonal ε_θ(x_t, t) block between each pair. Far-right curved arrow "T diffusion steps" connecting top-right to bottom-right; far-left curved arrow "sample x_0" connecting bottom-left to top-left. Title: "Denoising Diffusion: forward corruption and learned reverse". Subtitle: "Ho et al., 2020".
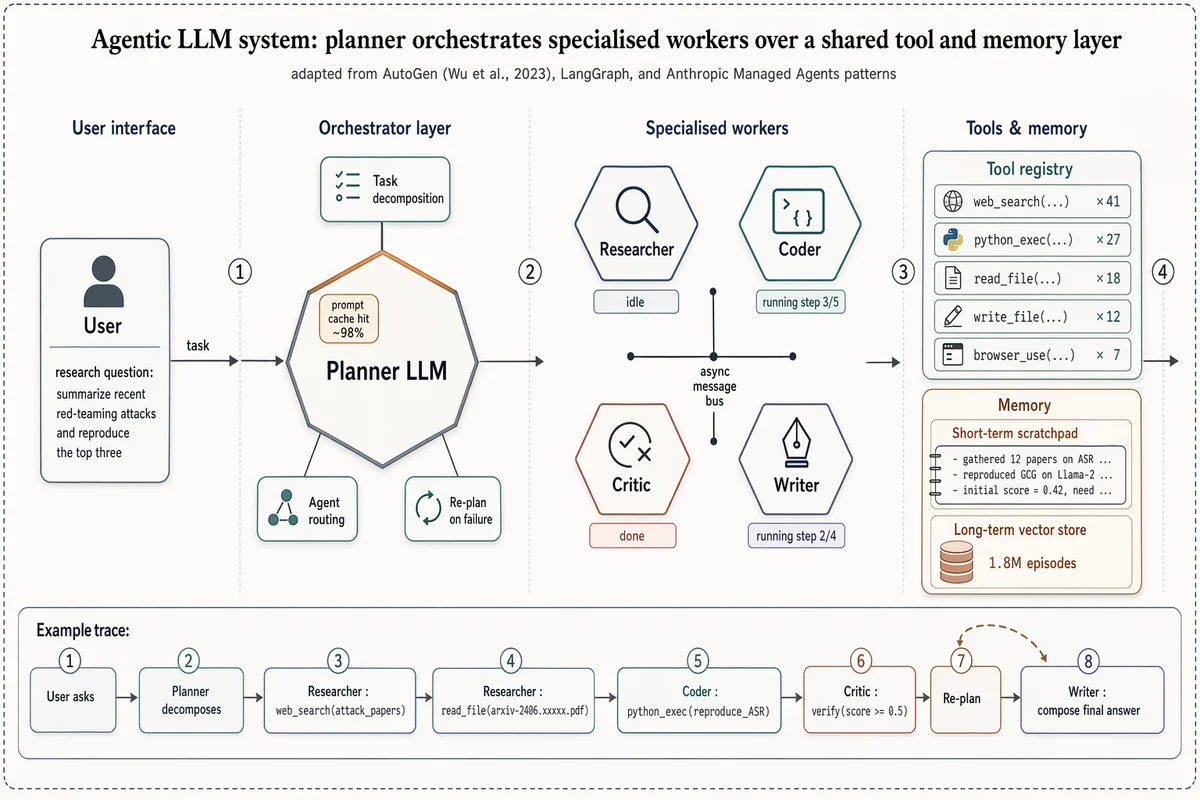
Arquitetura de sistema multi-agente com LLM
Landscape 16:9 high-fidelity systems figure of a multi-agent LLM architecture, in the style of a richly detailed AutoGen / LangGraph / Anthropic Managed Agents Figure 1. Subtle drop-shadows, warm-copper highlights, numbered flow markers ①②③④. ZONE 1 — "User interface": rounded user box with placeholder task "research question: summarize recent red-teaming attacks and reproduce the top three". ZONE 2 — "Orchestrator layer": central hexagonal hub "Planner LLM" with warm-copper top edge. Three satellite chips: "Task decomposition", "Agent routing", "Re-plan on failure". Small inset chip "prompt cache hit ~98%". ZONE 3 — "Specialised workers": 2×2 hexagons "Researcher" / "Coder" / "Critic" / "Writer", each with glyph + status ribbon ("idle", "running step 3/5", "done", "running step 2/4"). Centre labeled "async message bus". ZONE 4 — "Tools & memory": (a) "Tool registry" panel listing "web_search ×41", "python_exec ×27", "read_file ×18", "write_file ×12", "browser_use ×7"; (b) "Memory" panel with "Short-term scratchpad" and cylinder "Long-term vector store — 1.8M episodes". Bottom inset "Example trace": 8-step horizontal timeline chips from "User asks" through "Planner decomposes", "Researcher: web_search(...)", "Coder: python_exec(...)", "Critic: verify", "Re-plan" (loop-back arrow), "Writer: compose final answer". Title: "Agentic LLM system: planner orchestrates specialised workers over a shared tool and memory layer". Subtitle: "adapted from AutoGen (Wu et al., 2023), LangGraph, and Anthropic Managed Agents patterns".
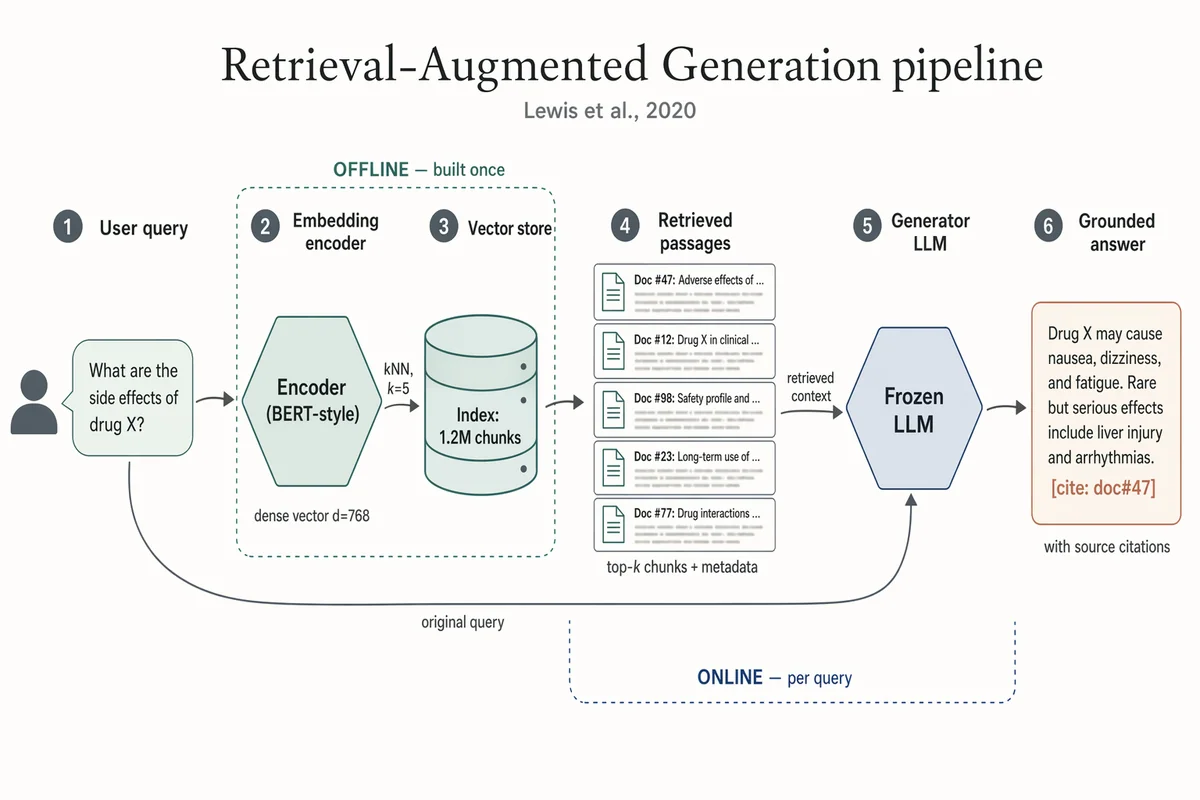
Pipeline de Geração Aumentada por Recuperação (RAG)
Landscape 16:9 academic systems diagram of a RAG pipeline, 6-stage left-to-right flow. (1) "User query" box with placeholder text "What are the side effects of drug X?" and a small user silhouette. (2) Hexagonal "Embedding encoder (BERT-style)", caption "dense vector d=768". (3) Stylised database cylinder "Vector store" with "Index: 1.2M chunks"; arrow from (2) labeled "kNN, k=5". (4) "Retrieved passages" — stack of 5 doc thumbnails; caption "top-k chunks + metadata". (5) Hexagonal hub "Frozen LLM"; long curved arrow from (1) labeled "original query" also lands here; arrow from (4) labeled "retrieved context". (6) "Grounded answer" with inline marker "[cite: doc#47]"; caption "with source citations". Dashed outline around (2)-(3) labeled "OFFLINE — built once". Dashed outline around (4)-(5) labeled "ONLINE — per query". Title: "Retrieval-Augmented Generation pipeline". Subtitle: "Lewis et al., 2020".
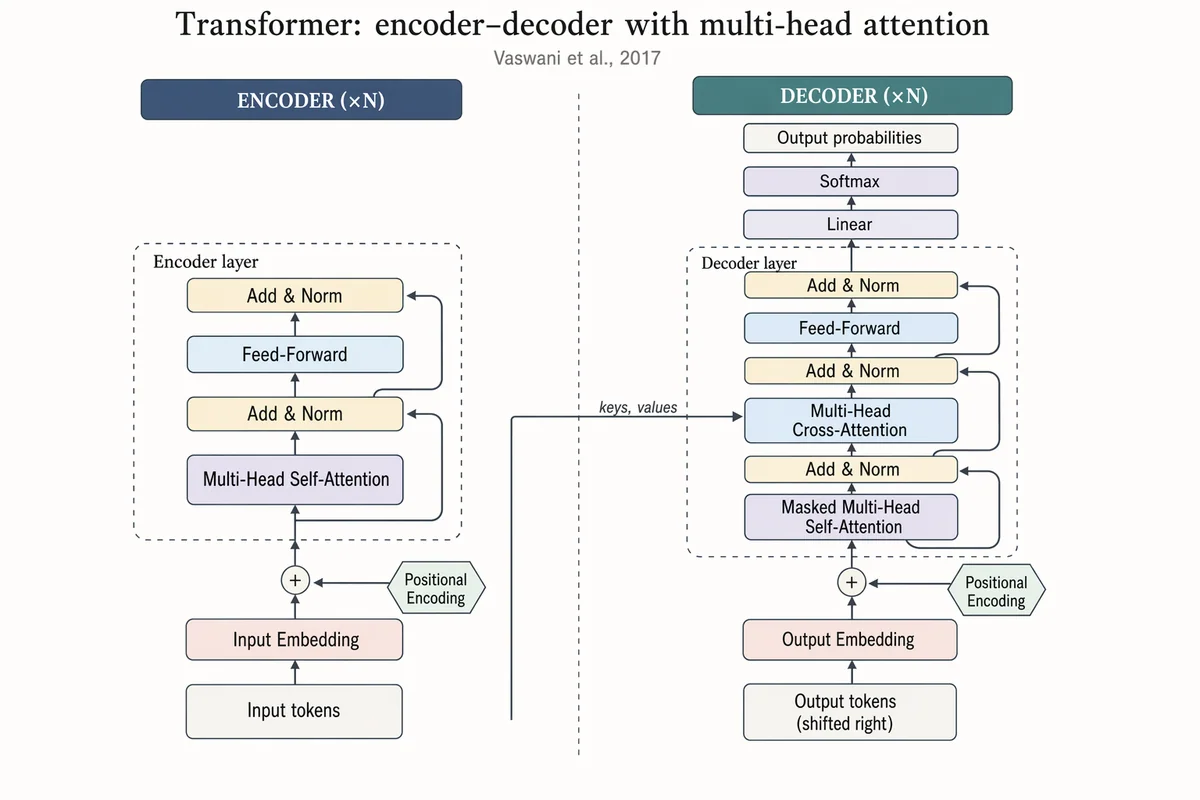
Arquitetura encoder–decoder Transformer
Landscape 16:9 academic concept figure of the Transformer encoder-decoder architecture, NeurIPS camera-ready style. Two vertical column stacks side-by-side with a dashed divider. LEFT column header: "ENCODER (×N)". Blocks bottom-to-top: "Input tokens" → "Input Embedding" → "+ Positional Encoding" → dashed "Encoder layer" containing "Multi-Head Self-Attention", "Add & Norm", "Feed-Forward", "Add & Norm", with thin curved residual arrows around each sublayer. RIGHT column header: "DECODER (×N)". Blocks bottom-to-top: "Output tokens (shifted right)" → "Output Embedding" → "+ Positional Encoding" → dashed "Decoder layer" containing "Masked Multi-Head Self-Attention", "Add & Norm", "Multi-Head Cross-Attention" (horizontal arrow from encoder top labeled "keys, values"), "Add & Norm", "Feed-Forward", "Add & Norm". Above decoder: "Linear", "Softmax", "Output probabilities". Title: "Transformer: encoder–decoder with multi-head attention". Subtitle: "Vaswani et al., 2017".