循環器系 ポスター
他のインフォグラフィック
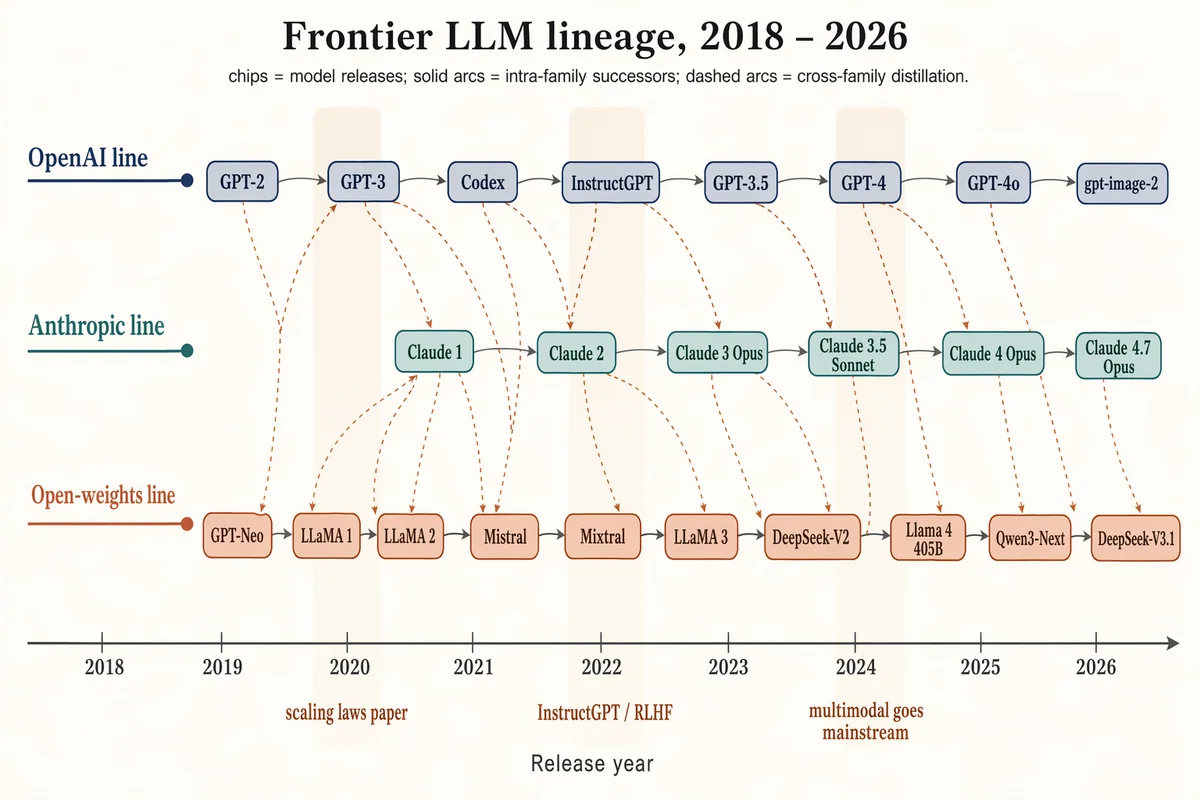
フロンティアLLM家系図(2018–2026)
Landscape 16:9 timeline / family tree of frontier LLMs 2018–2026, three vertically stacked lanes over a horizontal time axis. Time axis ticks: "2018", "2019", "2020", "2021", "2022", "2023", "2024", "2025", "2026". LANE 1 (top, muted navy) "OpenAI line": chips "GPT-2", "GPT-3", "Codex", "InstructGPT", "GPT-3.5", "GPT-4", "GPT-4o", "gpt-image-2". LANE 2 (middle, dusty teal) "Anthropic line": chips "Claude 1", "Claude 2", "Claude 3 Opus", "Claude 3.5 Sonnet", "Claude 4 Opus", "Claude 4.7 Opus". LANE 3 (bottom, soft terracotta) "Open-weights line": chips "GPT-Neo", "LLaMA 1", "LLaMA 2", "Mistral", "Mixtral", "LLaMA 3", "DeepSeek-V2", "Llama 4 405B", "Qwen3-Next", "DeepSeek-V3.1". Solid slate-gray arcs = intra-family successors; warm-copper dashed arcs = cross-family distillation. Soft vertical highlight bands at 2020 ("scaling laws paper"), 2022 ("InstructGPT / RLHF"), 2024 ("multimodal goes mainstream"). Title: "Frontier LLM lineage, 2018 – 2026". Subtitle: "chips = model releases; solid arcs = intra-family successors; dashed arcs = cross-family distillation."
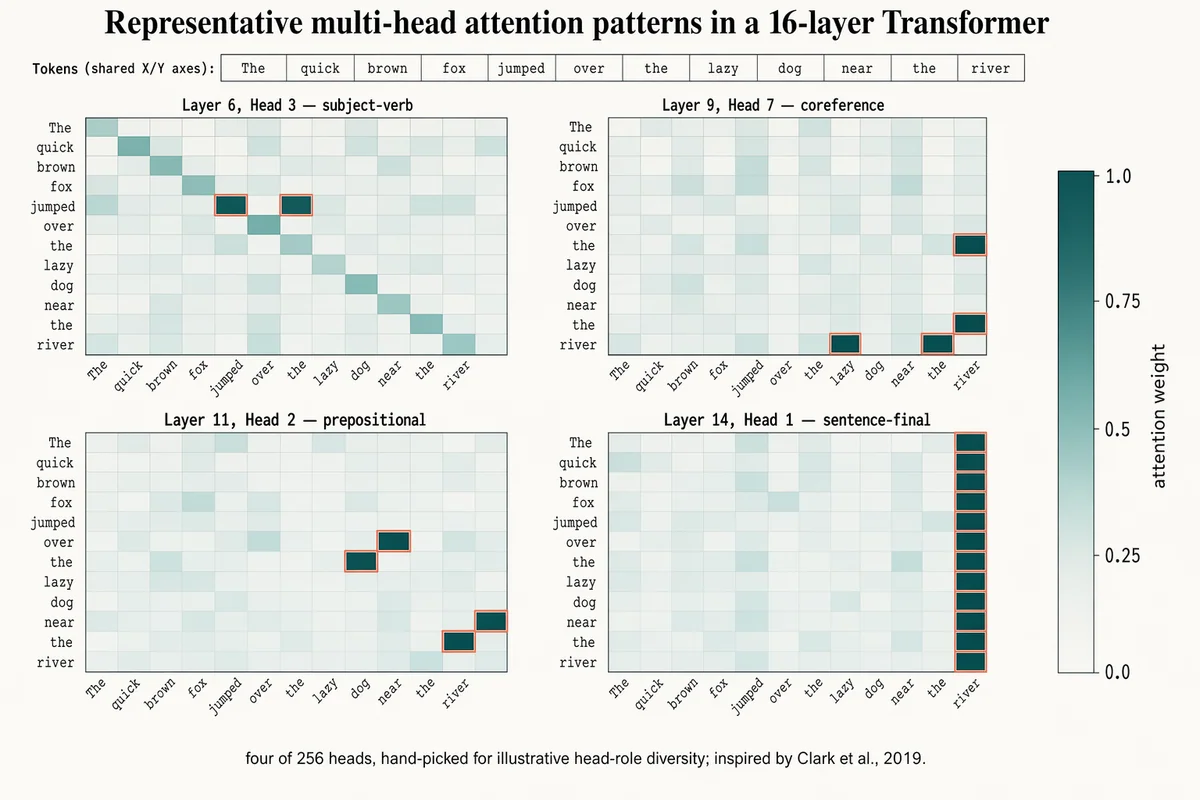
マルチヘッド・アテンション ヒートマップ
Landscape 16:9 figure of 4 attention heatmaps (2×2 grid), shared 12-token input. Token labels across X and Y (rotated 45° on X): "The", "quick", "brown", "fox", "jumped", "over", "the", "lazy", "dog", "near", "the", "river". Four 12×12 cell panels with individual titles: "Layer 6, Head 3 — subject-verb" (highlighted cells between "fox"/"jumped") "Layer 9, Head 7 — coreference" (highlighted cells between "the"(×2)/"river") "Layer 11, Head 2 — prepositional" (highlighted cells between "over"/"dog", "near"/"river") "Layer 14, Head 1 — sentence-final" (activity concentrated in rightmost column) Cells: dusty-teal gradient, darker = higher weight. Peak cells outlined in 1px soft-terracotta. Shared vertical color bar on far right with ticks "0.0", "0.25", "0.5", "0.75", "1.0" and label "attention weight". Title: "Representative multi-head attention patterns in a 16-layer Transformer". Subtitle: "four of 256 heads, hand-picked for illustrative head-role diversity; inspired by Clark et al., 2019."
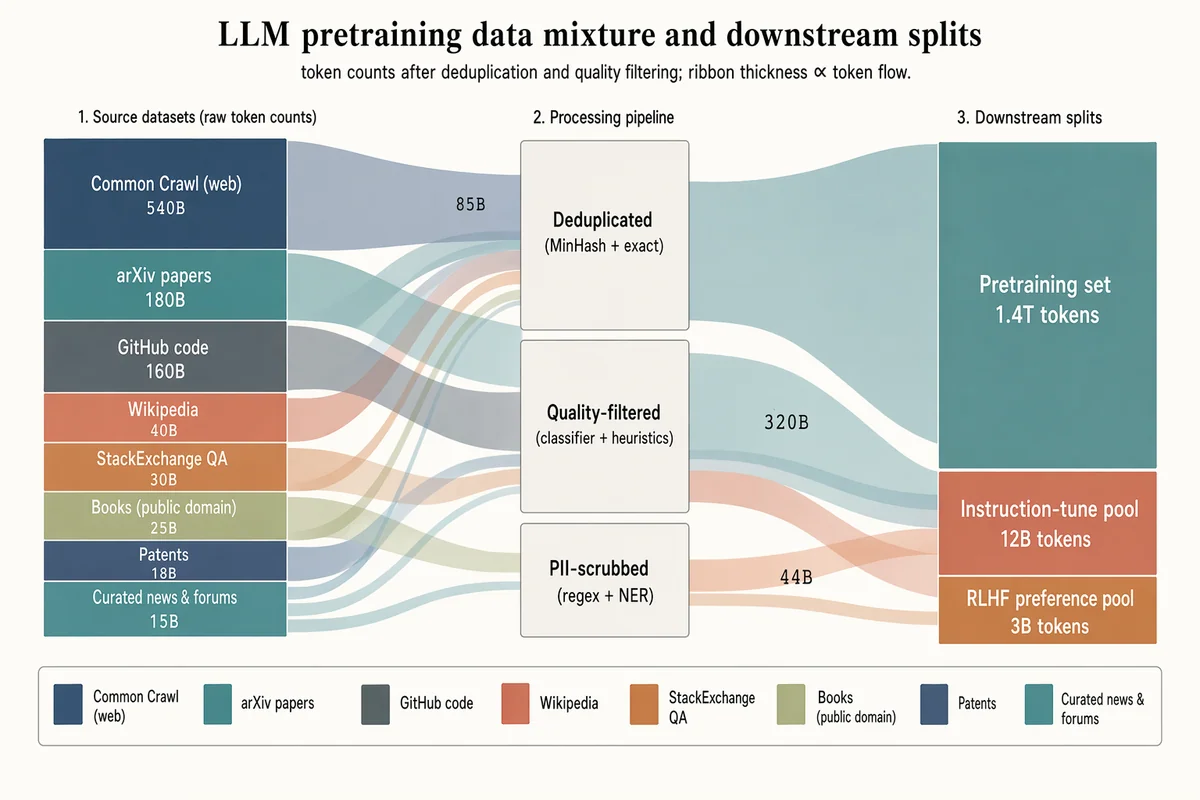
LLM事前学習データミックス サンキー図
Landscape 16:9 sankey diagram of a pretraining data mixture, three stages with translucent colored ribbons. LEFT (8 source blocks, heights proportional to tokens): "Common Crawl (web) 540B" (muted navy, largest), "arXiv papers 180B" (dusty teal), "GitHub code 160B" (slate gray), "Wikipedia 40B" (soft terracotta), "StackExchange QA 30B" (warm copper), "Books (public domain) 25B" (pale olive), "Patents 18B" (pale navy), "Curated news & forums 15B" (dusty teal). MIDDLE (3 processing blocks, stacked): "Deduplicated (MinHash + exact)", "Quality-filtered (classifier + heuristics)", "PII-scrubbed (regex + NER)". RIGHT (3 final splits): "Pretraining set 1.4T tokens" (largest), "Instruction-tune pool 12B tokens", "RLHF preference pool 3B tokens". Flow ribbons inherit source color with mid-labels showing token counts ("85B", "320B", "44B"). Legend strip at bottom. Title: "LLM pretraining data mixture and downstream splits". Subtitle: "token counts after deduplication and quality filtering; ribbon thickness ∝ token flow."
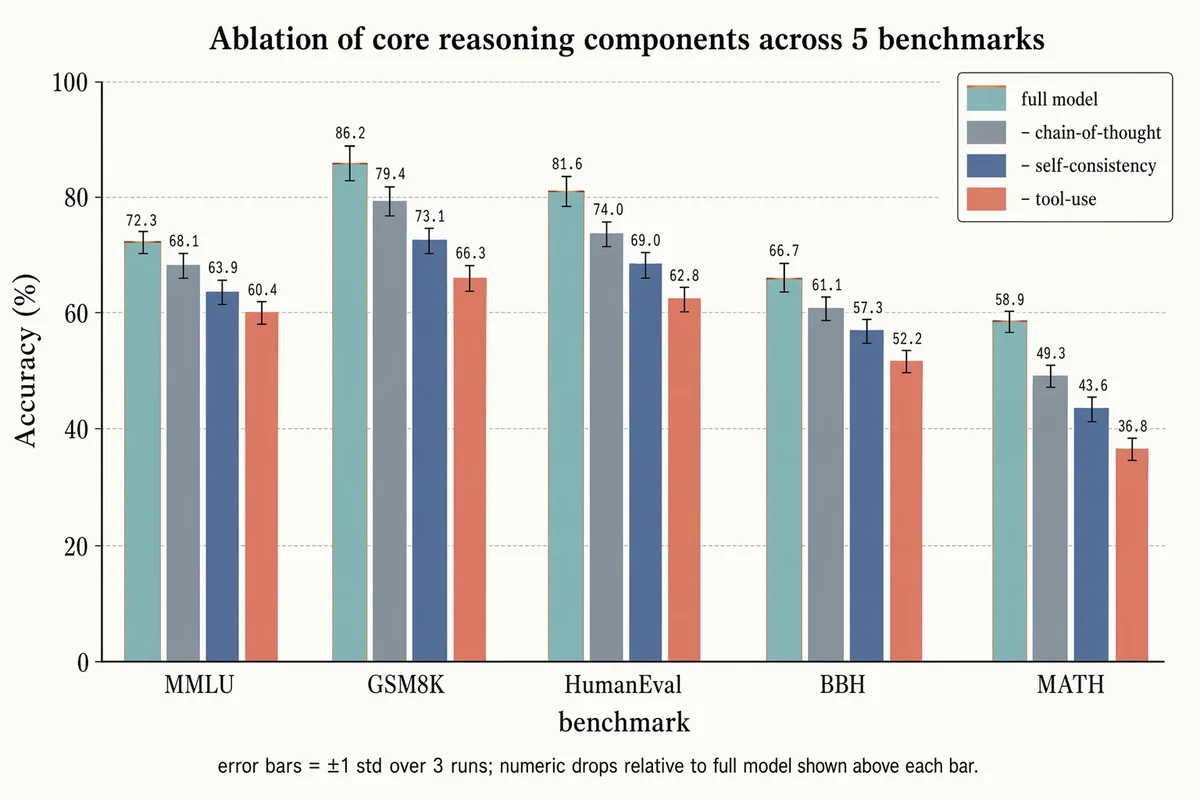
アブレーション棒グラフ(エラーバー付き)
Landscape 16:9 grouped-bar ablation chart. X-axis: 5 benchmark groups "MMLU", "GSM8K", "HumanEval", "BBH", "MATH". Y-axis "Accuracy (%)" with ticks "0", "20", "40", "60", "80", "100". Each group has 4 bars side-by-side: (1) "full model" — dusty-teal with thin warm-copper top outline (2) "– chain-of-thought" — slate gray (3) "– self-consistency" — muted navy (4) "– tool-use" — soft terracotta Thin black ±1σ error bars on each; numeric label above each bar in monospace. Faint horizontal gridlines. Legend box top-right. Title: "Ablation of core reasoning components across 5 benchmarks". Subtitle: "error bars = ±1 std over 3 runs; numeric drops relative to full model shown above each bar."
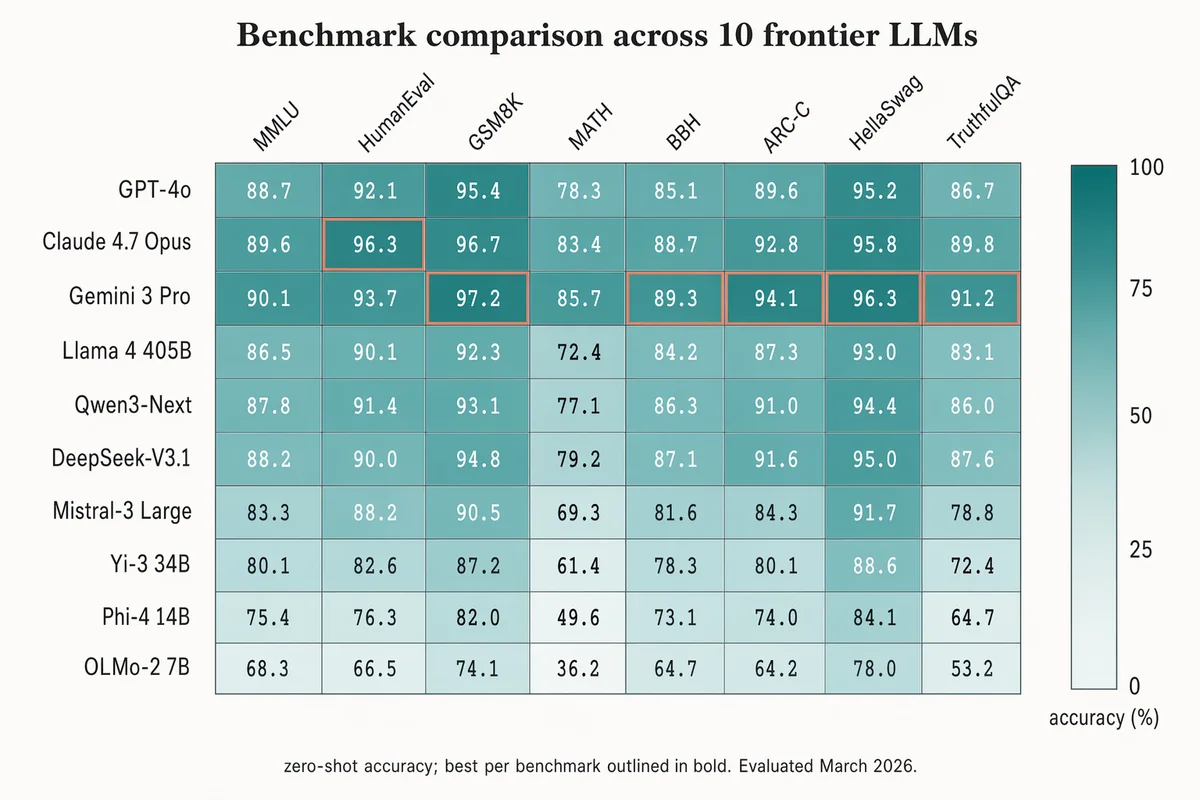
ベンチマーク比較ヒートマップ
Landscape 16:9 heatmap matrix of models × benchmarks. Columns (rotated 45°): "MMLU", "HumanEval", "GSM8K", "MATH", "BBH", "ARC-C", "HellaSwag", "TruthfulQA". Rows (right-aligned sans-serif): "GPT-4o", "Claude 4.7 Opus", "Gemini 3 Pro", "Llama 4 405B", "Qwen3-Next", "DeepSeek-V3.1", "Mistral-3 Large", "Yi-3 34B", "Phi-4 14B", "OLMo-2 7B". Each cell filled with dusty-teal gradient proportional to score; numeric value in each cell (e.g. "72.3", "88.1"). Best score per column outlined in 1.5px soft-terracotta. Vertical color bar on the right with ticks "0", "25", "50", "75", "100" and label "accuracy (%)". Title: "Benchmark comparison across 10 frontier LLMs". Subtitle: "zero-shot accuracy; best per benchmark outlined in bold. Evaluated March 2026."
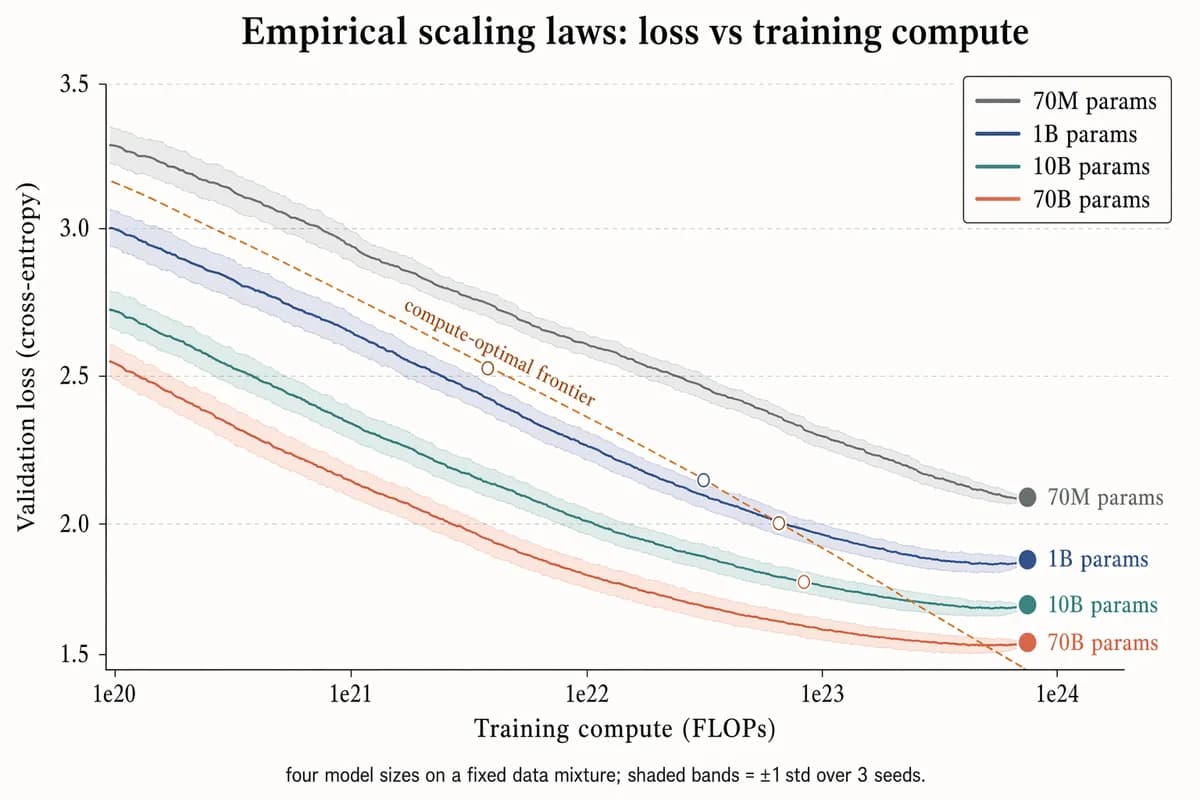
経験的スケーリング則 プロット
Landscape 16:9 log-scaled plot of training loss vs compute, four curves for different model sizes. X-axis "Training compute (FLOPs)" with log ticks "1e20", "1e21", "1e22", "1e23", "1e24". Y-axis "Validation loss (cross-entropy)" with linear decreasing ticks "3.5", "3.0", "2.5", "2.0", "1.5". Four descending curves with ±1σ shaded bands, labels near tails: "70M params" (slate gray), "1B params" (muted navy), "10B params" (dusty teal), "70B params" (soft terracotta). Warm-copper dashed diagonal line labeled "compute-optimal frontier"; open circles at isoflop crossover points. Legend box top-right. Title: "Empirical scaling laws: loss vs training compute". Subtitle: "four model sizes on a fixed data mixture; shaded bands = ±1 std over 3 seeds."